
Advanced Xpath Concept – Method normalize-space & Its Usage
Hello Folks,
In this post we will going to learn an advanced concept of xpath: – normalize-space method.
Before we discuss about method normalize-space, we will see why do we require that.
Consider below html codes:
<anyTag> Make Selenium Easy </anyTag> (Inner text has more white spaces among words than normal.)
It will be displaying correctly at Front End (FE) but in DOM, it is in different way i.e. containing uneven white spaces among words.
<anyTag> Make Selenium Easy </anyTag> (Inner text has spaces in beginning and end.)
Innex text has spaces in beginning and end of inner text. You may just need to trim those white spaces.
The same can be the case with attribute as well as shown below:
<anyTag class=” some name with more spaces”> </anyTag>
All above examples have spaces and you may need to locate them by removing unwanted white spaces. Obviously we have a method named “contains” but it will not work if there are more than one white spaces between words. Here, normalize-space method will be useful.
Let’s see some examples below:
Scenario 1: Text or attribute value with white spaces in beginning and end:
<a id=" someAnchor " class="mce-item-anchor"> Text with trailing whitespaces </a>
Text or InnerText:
In above code, you can see inner text of tag ‘a’ has white spaces in the beginning and end. We can use contains here as below:
XPath using contains method:
//a[contains(text(),’Text with trailing whitespaces’)]
The same can be achieved using normalize-space method:
//a[normalize-space(text())=’Text with trailing whitespaces’]
Attribute Value:
XPath using contains method:
//a[contains(@id,’someAnchor’)]
The same can be achieved using normalize-space method:
//a[normalize-space(@id)=’someAnchor’]
Scenario 2: Text or attribute value with uneven white spaces in between of words:
<a id=" someAnchor " class="mce-item-anchor"> Text with uneven whitespaces </a>
You can see in UI, it displays correctly but html contains uneven white spaces.
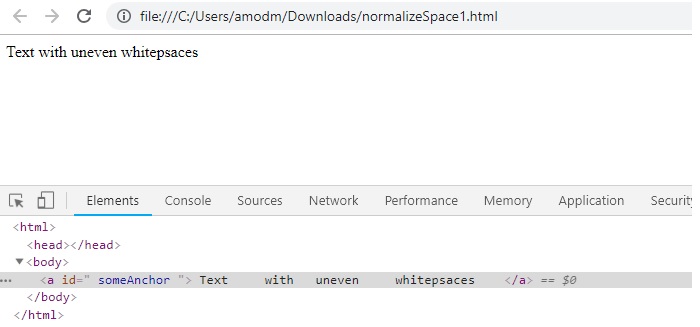
In this case, contains will not work. We need to use normalize-space method because it just not trim white spaces from beginning and end of string, also between words as well.
//a[normalize-space(text())=’Text with uneven whitespaces’]
Scenario 3: Nested elements with inner Text
Consider below nested element with inner text:
<label> some label <span>some span</span> </label>
You can see label tag has innertext as “some label” and span tag has innertext as “some span”. First outer element has innertext followed by inner element innertext.
You can easily locate it using contains as below:
//label[contains(text(),’some label’)]
But problem happens when outer element innertext comes after inner element innertext. Example:
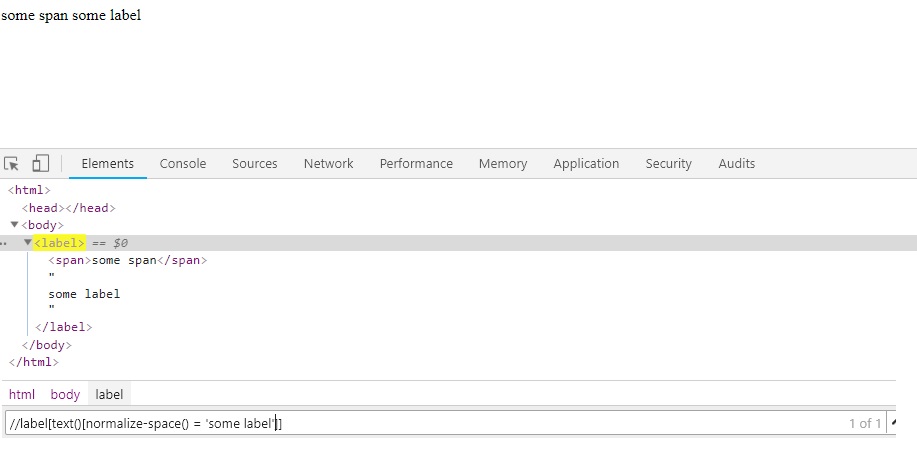
<label> <span>some span</span> some label </label>
In this case contains method will not work. You need to use normalize-space method. But here syntax will be little different as :
//label[text()[normalize-space() = ‘some label’]]
Hope you learnt something new and will be useful in locating elements.
If you have any doubt, feel free to comment below.
If you like my posts, please like, comment, share and subscribe.
#ThanksForReading
#HappySelenium
helllo Amod sir
website–https://coinmarketcap.com/currencies/oddz/markets/
i just want to import this table 1 row or multiple rows live data in google sheet via
xpath.please tell me xpath
please help me.i am in big trouble
Hi Amol,
I have html as follow :
“Docs “
Here I am not able to locate with ‘Docs”.
I tried using //a[text()[normalize-space() = ‘Docs’]]
Very useful. Thanks a lot
i tried your scenario 3 but i am not able to do, may be somewhere i go in a wrong direction. so can you share with better explanation or through a program
Hi Manoj,
Kindly let me know what you have tried or problem faced.
Thanks
Amod